
近日,来自 Databricks 的 Matei Zaharia 开源机器学习平台 MLflow 。Matei Zaharia 是 和 的核心作者,也是 Databrick 的首席技术专家。Databrick 是由 Apache Spark 技术团队所创立的商业化公司。MLflow 目前已处于早期测试阶段,开发者可下载源码体验。

Matei Zaharia 表示当前在使用机器学习的公司普遍存在工具过多、难以跟踪实验、难以重现结果、难以部署等问题。为让机器学习开发变得与传统软件开发一样强大、可预测和普及,许多企业已开始构建内部机器学习平台来管理 ML生命周期。像是 Facebook、Google 和 Uber 就已分别构建了 、 和 来管理数据、模型培训和部署。不过由于这些内部平台存在局限性和绑定性,无法很好地与社区共享成果,其他用户也无法轻易使用。
MLflow 正是受现有的 ML 平台启发,主打开放性:
开放接口:可与任意 ML 库、算法、部署工具或编程语言一起使用。
开源:开发者可轻松地对其进行扩展,并跨组织共享工作流步骤和模型。
MLflow 目前的 alpha 版本包含三个组件:
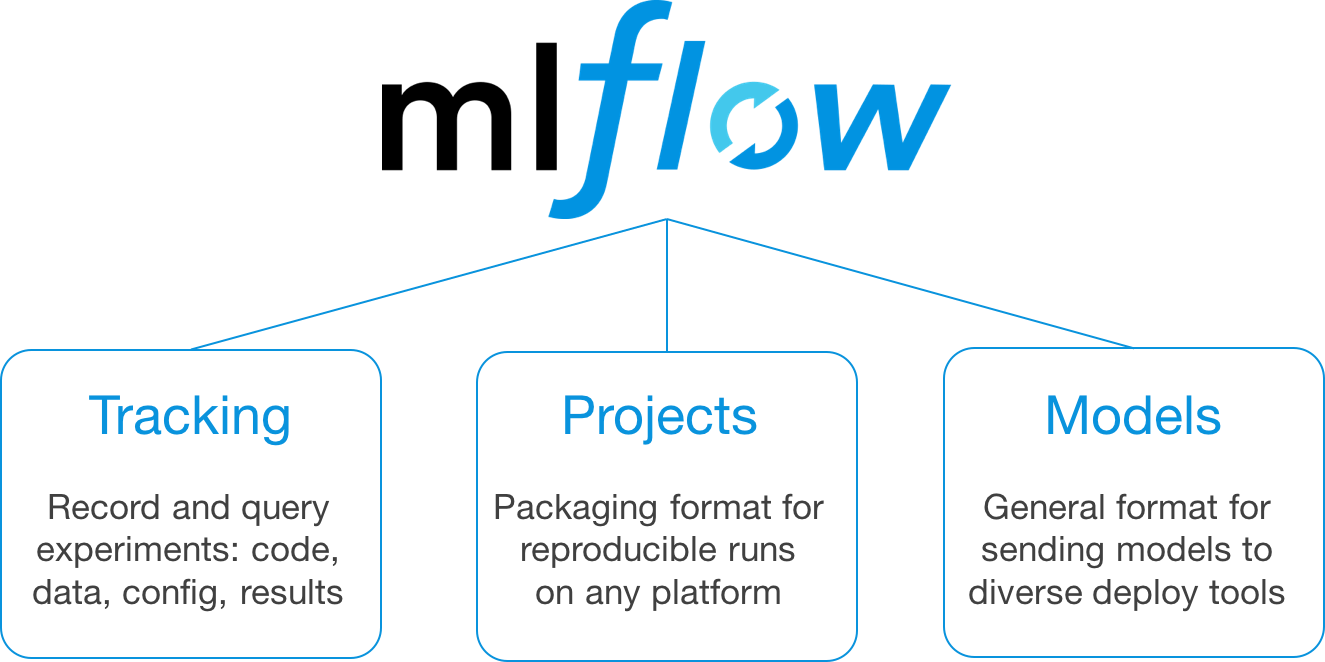
其中,MLflow Tracking(跟踪组件)提供了一组 API 和用户界面,用于在运行机器学习代码时记录和查询参数、代码版本、指标和输出文件,以便以后可视化它们。
import mlflow# Log parameters (key-value pairs)mlflow.log_param("num_dimensions", 8)mlflow.log_param("regularization", 0.1)# Log a metric; metrics can be updated throughout the runmlflow.log_metric("accuracy", 0.1)...mlflow.log_metric("accuracy", 0.45)# Log artifacts (output files)mlflow.log_artifact("roc.png")mlflow.log_artifact("model.pkl")
MLflow Projects(项目组件)提供了打包可重用数据科学代码的标准格式。每个项目都只是一个包含代码或 Git 存储库的目录,并使用一个描述符文件来指定它的依赖关系以及如何运行代码。每个 MLflow 项目都是由一个简单的名为 MLproject 的 YAML 文件进行自定义。
name: My Projectconda_env: conda.yamlentry_points: main: parameters: data_file: path regularization: {type: float, default: 0.1} command: "python train.py -r {regularization} {data_file}" validate: parameters: data_file: path command: "python validate.py {data_file}"
MLflow Models(模型组件)提供了一种用多种格式打包机器学习模型的规范,这些格式被称为 “flavor” 。MLflow 提供了多种工具来部署不同 flavor 的模型。每个 MLflow 模型被保存成一个目录,目录中包含了任意模型文件和一个 MLmodel 描述符文件,文件中列出了相应的 flavor 。
time_created: 2018-02-21T13:21:34.12flavors: sklearn: sklearn_version: 0.19.1 pickled_model: model.pkl python_function: loader_module: mlflow.sklearn pickled_model: model.pkl